案例分析:基于Pandas的数据处理插件开发
在使用Coze工作流(Workflow)编排自动化任务时,我们经常会用到「代码块」(本文针对Python语言)来执行自定义逻辑。但如果你深入开发过,就会发现一个隐秘的限制:
Coze工作流内置的Python代码块,对第三方库支持非常有限,尤其是像 pandas、openpyxl 这样的重量级依赖,经常无法直接使用,在 Python 环境中,仅内置了两个第三方依赖库:requests_async 和 numpy。官方使用说明
那有没有办法突破这一限制,在Coze里灵活使用各种Python库,执行更复杂的逻辑呢?
答案是——开发自定义插件(Plugin)!
这篇文章将通过一个实战案例,教你如何绕过代码块的依赖限制,自由调用Pandas来处理Excel数据。
问题背景:Coze代码块的局限
Coze官方文档中提到,代码块运行环境默认只支持部分基础Python库,如:
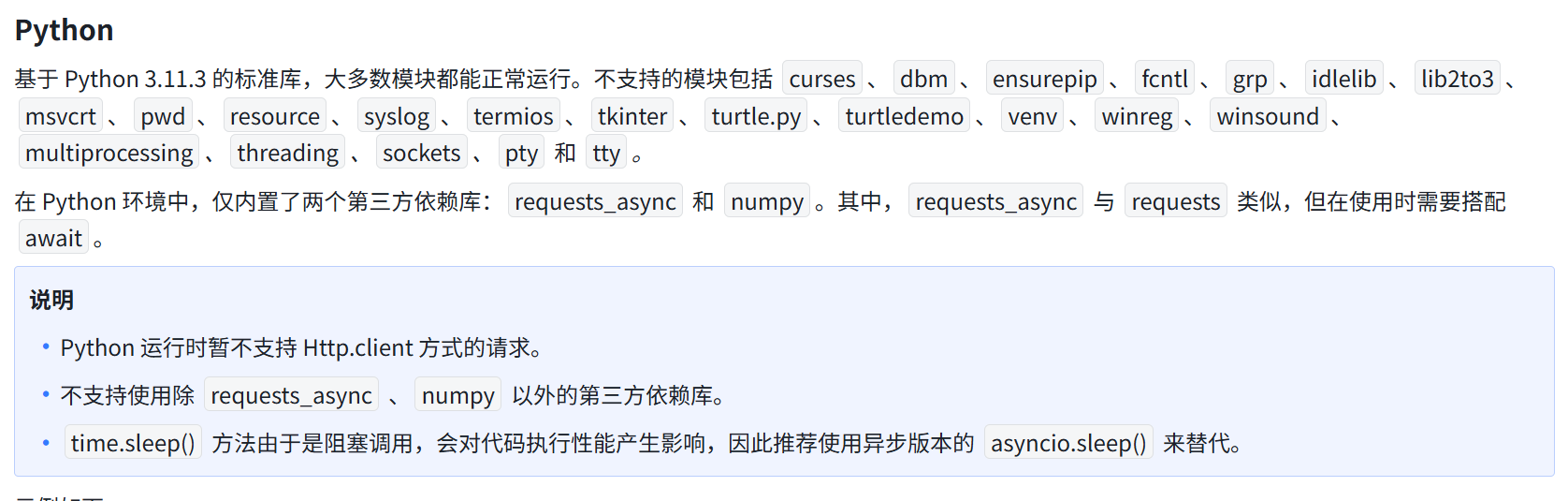
而像 pandas、requests 这类第三方库,往往是不支持的。即使你在代码中导入了它们,也会报错:
1
|
ModuleNotFoundError: No module named 'pandas'
|
这使得很多数据处理、文件解析、网络请求等需求,难以直接用原生代码块完成。
解决方案:开发插件(Plugin)
Coze允许开发者自定义插件,通过独立服务或Coze托管运行插件代码。这种方式拥有更完整的Python环境支持,可以自由安装依赖包,极大扩展了功能边界。
比如,我开发了一个叫 Exec_Code 的插件,它支持:
- 在线下载指定的Excel文件
- 执行任意Pandas数据处理代码
- 返回处理后的结果,供后续流程继续使用
插件功能概览
-
输入参数:
files: Excel文件的URL地址code_block: 要执行的Pandas代码片段
-
使用依赖库:
pandas:数据处理openpyxl:解析Excelpydantic:参数校验requests:文件下载
-
核心逻辑:
- 下载并读取Excel文件(支持多Sheet)
- 安全执行用户提供的代码块
- 强制要求代码块输出
result 变量
- 自动将DataFrame或复杂对象转换为JSON返回
插件核心代码解析
这里简单拆解一下主要逻辑:
1. 下载并读取Excel文件
1
2
|
response = requests.get(str(input_args.files), timeout=10)
sheets_dict = pd.read_excel(BytesIO(response.content), sheet_name=None)
|
通过requests获取文件,通过pandas一次性读取全部Sheet成字典 {sheet_name: DataFrame}。
2. 安全执行Pandas代码块
为了避免执行恶意代码,定义了一个受限版的globals环境,只允许部分内置函数和必要模块(pandas、json):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
safe_globals = {
'__builtins__': {
'print': print,
'len': len,
...
},
'pd': pd,
'json': json,
}
local_vars = {
'files': sheets_dict,
'result': None
}
exec(input_args.code_block, safe_globals, local_vars)
|
这样,即使是用户自定义的代码,也可以保证一定程度的安全性。
3. 强制要求输出result
所有用户的Pandas逻辑,必须赋值给result 变量,否则插件会直接返回错误提示。
1
2
|
if 'result' not in local_vars:
return PluginOutput(status="error", error="代码块未定义 result 变量")
|
这样可以标准化输出,保证后续节点能正确使用结果。
4. 结果处理与序列化
Pandas的DataFrame、复杂对象,默认是无法直接转成JSON的。因此,写了一个递归函数 convert_to_serializable,确保输出最终可JSON化。
1
2
3
4
|
if isinstance(result, pd.DataFrame):
result = {'json_result': json.dumps(result.to_dict(orient='records'), ensure_ascii=False)}
else:
result = convert_to_serializable(result)
|
使用效果示例
假设我有一个Excel,里面是销售数据,想要提取某个Sheet的总销售额。
可以在Coze工作流中这样调用插件:
1
2
3
|
df = files["Sheet1"]
total_sales = df["销售额"].sum()
result = {"total_sales": total_sales}
|
执行后,插件返回:
1
2
3
4
5
6
|
{
"status": "success",
"result": {
"total_sales": 128000
}
}
|
是不是比在代码块中苦苦挣扎安装库、处理异常方便多了?
小结
总结一下:
| 问题 |
解决方案 |
| Coze代码块无法直接用第三方库 |
开发插件,运行在自由环境 |
| 想用Pandas、Requests等 |
在插件中声明依赖 |
| 保证安全执行动态代码 |
使用受限globals + 控制输出变量 |
插件的方式,不仅解锁了更多强大的Python能力,还能让你的Coze工作流更加灵活、强大!
插件商店搜索 ’Exec_Code’ 立即体验!

附:完整插件源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
|
from runtime import Args
from typings.exec2.exec2 import Input, Output
from pydantic import BaseModel, HttpUrl
import pandas as pd
import requests
from io import BytesIO
from typing import Optional, Dict
import logging
import json
# 输入模型
class PluginInput(BaseModel):
files: HttpUrl # 单一 Excel 文件的 URL
code_block: str # 要执行的 Pandas 代码块
# 输出模型
class PluginOutput(BaseModel):
status: str # 执行状态(success 或 error)
result: Optional[dict] = None # 执行结果,需为字典格式
error: Optional[str] = None # 错误信息(如果有)
def convert_to_serializable(obj):
"""
递归地将对象转换为 JSON 可序列化格式,处理 DataFrame 和多 sheet 字典。
Args:
obj: 要转换的对象(例如 DataFrame、字典、列表等)
Returns:
JSON 可序列化对象(dict、list、str、int、float、bool、None)
"""
logger = logging.getLogger(__name__)
if isinstance(obj, pd.DataFrame):
logger.info(f"Converting DataFrame to JSON string: {obj.shape}")
data = obj.to_dict(orient='records')
return json.dumps(data, ensure_ascii=False) # 确保中文字符正确编码
elif isinstance(obj, dict):
# 处理多 sheet 字典或其他字典类型
return {key: convert_to_serializable(value) for key, value in obj.items()}
elif isinstance(obj, list):
return [convert_to_serializable(item) for item in obj]
elif isinstance(obj, (int, float, str, bool)) or obj is None:
return obj
else:
logger.warning(f"Unsupported type {type(obj)} in result, converting to str")
return str(obj)
def handler(args: Args[Input]) -> Output:
"""
执行 Pandas 代码块,支持加载 Excel 文件的所有 sheet。
Parameters:
- args.input.files: 单一 Excel 文件的 URL
- args.input.code_block: 要执行的 Pandas 代码(必须赋值给 'result')
- args.logger: 日志记录器实例
Returns:
- PluginOutput 包含状态、结果和错误信息
"""
logger = args.logger or logging.getLogger(__name__)
logger.info("Starting PandasCodeExecutor plugin")
try:
# 验证输入
input_args = PluginInput(
files=args.input.files,
code_block=args.input.code_block
)
logger.info("Input validation passed")
# 检查输入是否为空
if not input_args.files:
logger.error("No file URL provided")
return PluginOutput(status="error", error="未提供文件 URL")
if not input_args.code_block.strip():
logger.error("Code block is empty")
return PluginOutput(status="error", error="代码块为空")
# 下载并读取 Excel 文件的所有 sheet
try:
response = requests.get(str(input_args.files), timeout=10)
response.raise_for_status()
# 使用 sheet_name=None 加载所有 sheet,返回 {sheet_name: DataFrame} 字典
sheets_dict = pd.read_excel(BytesIO(response.content), sheet_name=None)
logger.info(f"Successfully loaded {len(sheets_dict)} sheets from {input_args.files}: {list(sheets_dict.keys())}")
except requests.RequestException as e:
logger.error(f"Failed to download file {input_args.files}: {str(e)}")
return PluginOutput(status="error", error=f"下载文件失败: {str(e)}")
except pd.errors.ParserError as e:
logger.error(f"Failed to parse Excel file {input_args.files}: {str(e)}")
return PluginOutput(status="error", error=f"解析Excel文件失败: {str(e)}")
# 设置安全的执行环境
safe_globals = {
'__builtins__': {
'print': print,
'len': len,
'range': range,
'str': str,
'int': int,
'float': float,
'list': list,
'dict': dict,
'set': set,
'tuple': tuple,
'bool': bool,
'abs': abs,
'max': max,
'min': min,
'sum': sum,
'round': round,
'zip': zip,
},
'pd': pd, # 提供 pandas 库
'json': json # 提供 json 库
}
# 准备本地变量
local_vars = {
'files': sheets_dict, # 提供所有 sheet 的字典 {sheet_name: DataFrame}
'result': None # 用于存储 code_block 的输出
}
# 执行代码块
try:
exec(input_args.code_block, safe_globals, local_vars)
logger.info("Code block executed successfully")
except Exception as e:
logger.error(f"Code execution failed: {str(e)}")
logger.info(f"Code block: {input_args.code_block}")
return PluginOutput(status="error", error=f"代码执行失败: {str(e)}")
# 获取结果
if 'result' not in local_vars:
logger.error("Code block did not define 'result' variable")
return PluginOutput(status="error", error="代码块未定义 result 变量")
result = local_vars.get('result')
logger.info(f"Result type: {type(result)}, value: {result}")
if result is None:
logger.warning("No result assigned in code block")
return PluginOutput(status="success", error="代码块未赋值给result")
# 转换为 JSON 可序列化格式
if isinstance(result, pd.DataFrame):
result = {'json_result': json.dumps(result.to_dict(orient='records'), ensure_ascii=False)}
else:
result = convert_to_serializable(result)
logger.info(f"Converted result: {result}")
logger.info("Result processed for output")
# 验证 result 是否为字典
if not isinstance(result, dict):
logger.error(f"Result is not a dictionary: {type(result)}")
return PluginOutput(status="error", error=f"result 必须是字典,实际类型为 {type(result)}")
try:
return PluginOutput(status="success", result=result)
except Exception as e:
logger.error(f"Failed to create PluginOutput: {str(e)}")
return PluginOutput(status="error", error=f"无法序列化 result: {str(e)}")
except Exception as e:
logger.error(f"Plugin execution failed: {str(e)}")
return PluginOutput(status="error", error=str(e))
|